Autor: Mihai Nan
Într-o lume în care mesajele sunt tot mai scurte, tastate în grabă pe telefoane și distribuite instant pe rețelele sociale, calitatea limbajului scris începe să se degradeze. Greșeli de gramatică, cuvinte omise și formulări ambigue devin tot mai frecvente.
Pentru a analiza și îmbunătăți aceste texte, o platformă educațională dezvoltă un sistem automat capabil să transforme propozițiile scrise într-o manieră neatentă într-o variantă corectă și clară. Rolul tău este îi ajuți prin propunerea unui sistem automat care corectează textele, din perspectivă gramaticală.
Ai la dispoziție două fișiere:
Fiecare rând din train.csv are următoarele coloane:
SampleID — identificatorul unic al textuluiText — propoziția originală, așa cum a fost scrisă de utilizatorRevisedText — versiunea corectată de un expertExemplu:
SampleID,Text,RevisedText
747, "She forgot her umbrella it started to rain.", "She forgot her umbrella, and then it started to rain."
1382, "He could have bought the house if he has enough money.", "He could have bought the house if he had enough money."
241, "I have a meeting with a principal of a school.", "I have a meeting with the principal of the school."
Construiește un sistem care generează varianta corectă, din punct de vedere gramatical, pentru propozițiile din test.csv.
Sistemul de evaluare o să calculeze un scor final combinând două aspecte esențiale:
Formula de evaluare este:
final_score = 0.7 * cosine_similarity + 0.3 * edit_distance_score
Pentru a construi un sistem automat de corectare a textelor, evaluarea trebuie să țină cont atât de sensul propoziției, cât și de diferențele lexicale exacte. Aici intervin cosine_similarity și edit_distance.
Definiție:
Cosine similarity măsoară similaritatea dintre doi vectori calculând cosinusul unghiului dintre ei. Formula este:
A * B este produsul scalar al vectorilor|A| și |B| sunt normele lorÎn NLP:
Exemplu:
Text 1: "She forgot her umbrella."
Text 2: "She left her umbrella behind."
Relevanță:
Ne asigură că textul corectat păstrează aceeași idee ca textul original.
Definiție:
Edit distance măsoară numărul minim de operații (inserare, ștergere, înlocuire) necesare pentru a transforma un șir într-altul.
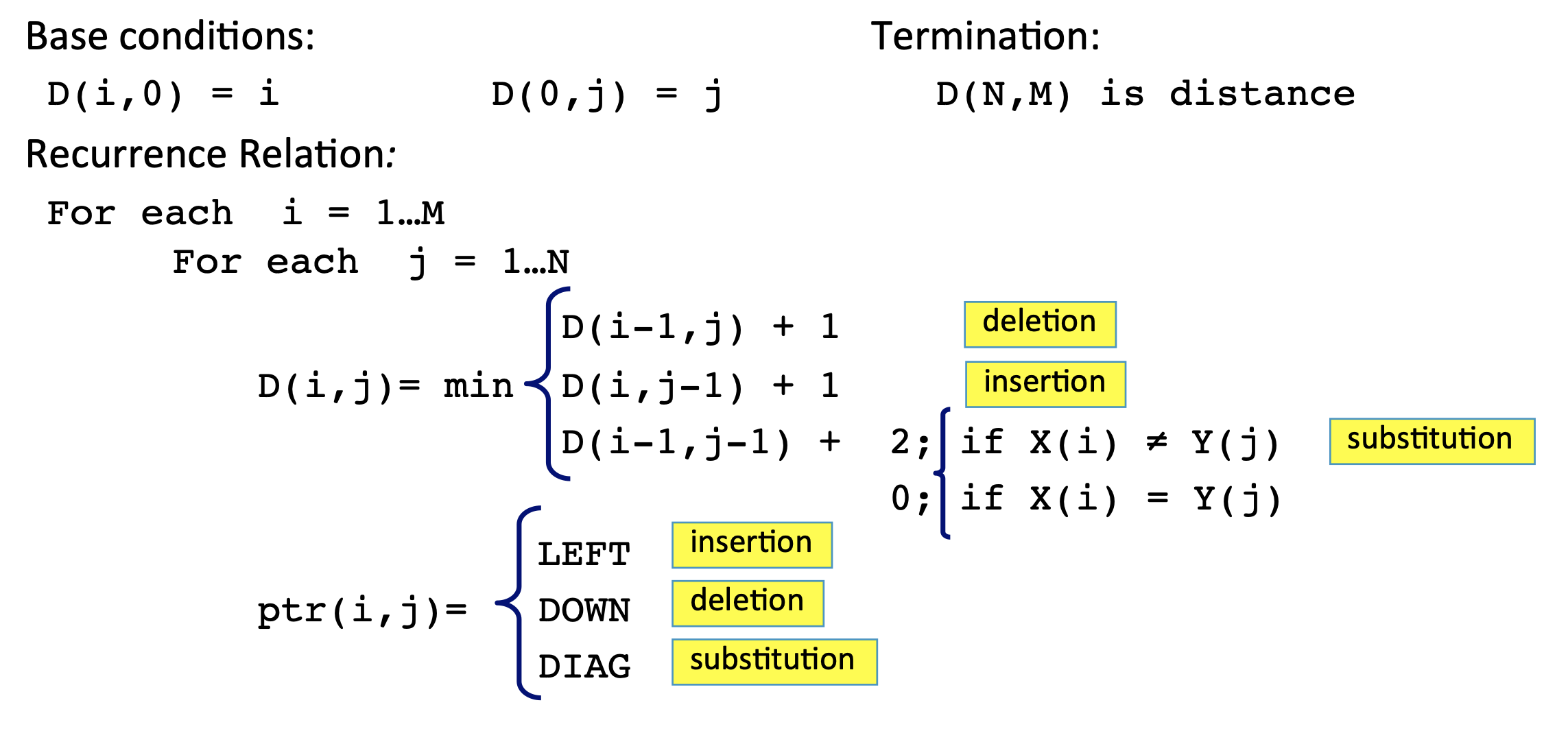
Exemplu:
Text original: "She forgot her umbrella it started to rain."
Text corectat: "She forgot her umbrella, and then it started to rain."
Relevanță:
Reflectă diferențele lexicale și corectitudinea gramaticală.
Formula scorului final:
Această combinație asigură că textul corectat este atât corect gramatical, cât și similar din punct de vedere semantic cu textul original.
Fișierul submission.csv trebuie să conțină un rând pentru fiecare text din test.
Prima linie a fișierului conține următoarele:
DatapointID, RevisedText
unde:
SampleID din test1557):1557, "He didn't eat any breakfast this morning."