Auteur: Mihai Nan
Compania ta dorește să protejeze utilizatorii de email-urile nedorite (spam).
Pentru aceasta, s-a decis construirea unui sistem automat care să identifice
email-urile spam și să le separe de cele legitime (nonspam).
Ai primit un set de email-uri etichetate și trebuie să construiești un model
care să poată clasifica email-urile noi.
Ți-au fost puse la dispoziție două fișiere:
label (spam = 1 / nonspam = 0)Scopul principal: predicția probabilității ca un email să fie spam (valoare între 0 și 1, unde 0 = nonspam sigur, 1 = spam sigur).
Fiecare rând reprezintă un email, cu următoarele atribute:
sample_id - identificator unictext - conținutul email-uluilabel - doar în train.csv, 1 (spam)/ 0 (nonspam)Scopul final: prezice label pentru rândurile din test.csv.
Primele două subtask-uri verifică analiza simplă a email-urilor.
Ultimul subtask evaluează modelul de clasificare.
Determină lungimea fiecărui email ca număr de caractere.
Afișează pentru acest subtask un număr întreg.
Numără câte apariții ale cuvântului free există în email.
Construiți un model de clasificare care prezice probabilitatea ca un email să fie spam (p ∈ [0,1]) pentru fiecare rând din test.
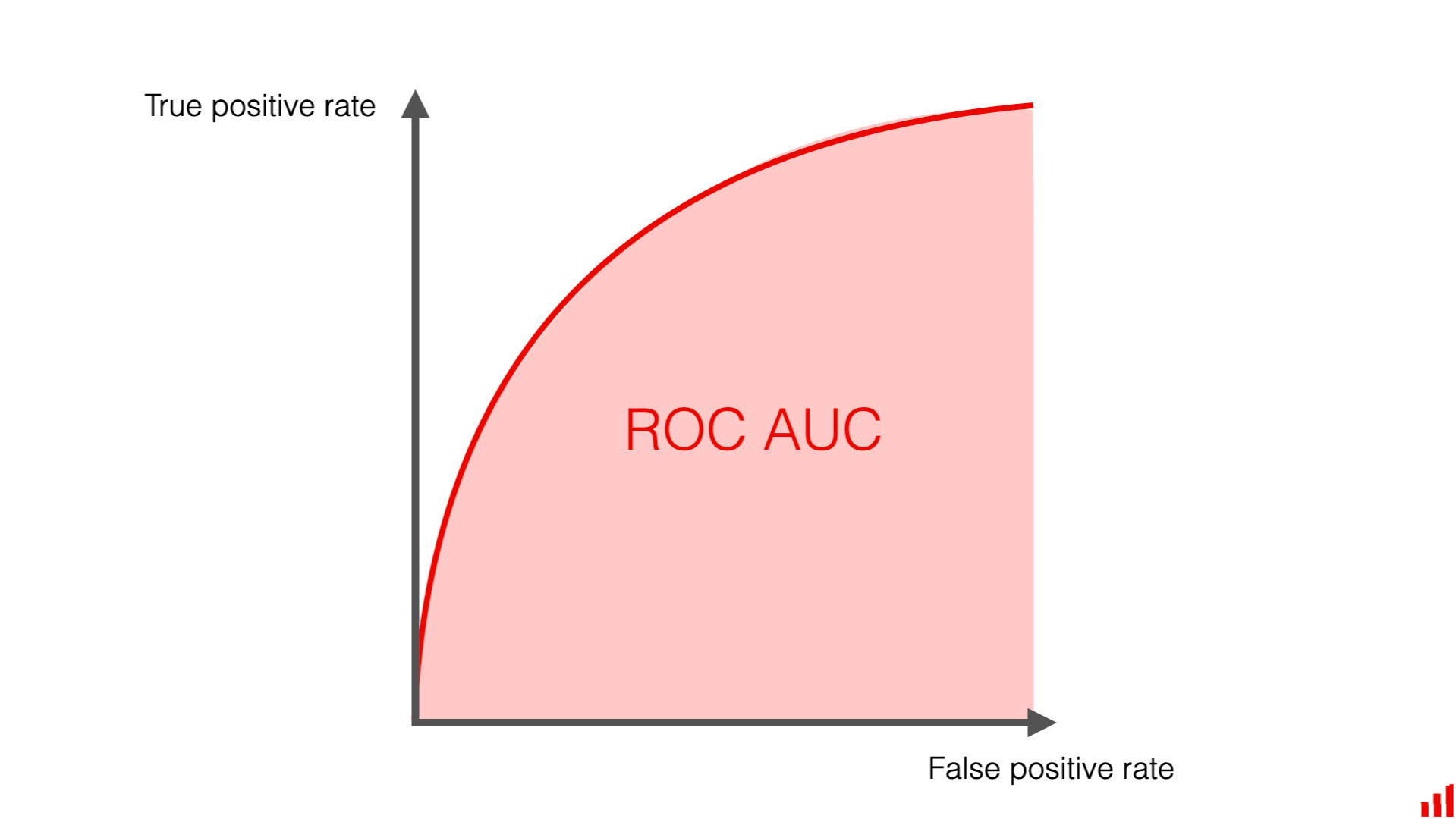
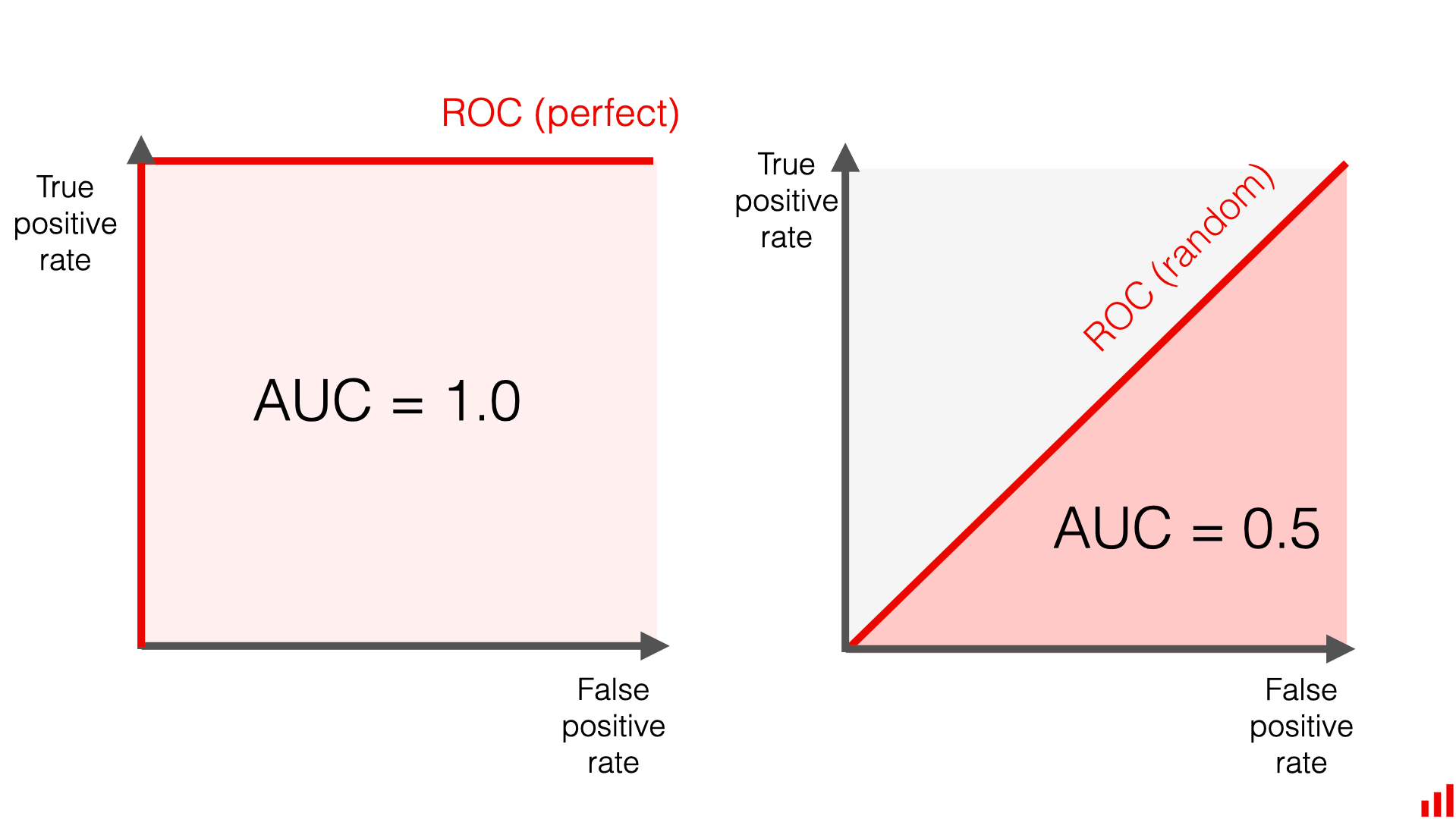
Evaluarea se face folosind ROC curve și AUC (Area Under the ROC Curve).
Subtasks 1–2 se evaluează exact (prin comparare).
Fișierul submission.csv trebuie să conțină câte 3 linii pentru fiecare rând din test,
corespunzătoare celor 3 subtasks.
Structură:
subtaskID, datapointID, answerunde:
sample_idfree (număr întreg)sample_id = 00042:subtaskID,datapointID,answer1,00042,3422,00042,33,00042,0.742Pentru Subtask 3, evaluarea se face folosind ROC AUC (Area Under the ROC Curve).
Aceasta este o măsură unică care sintetizează performanța unui clasificator pentru toate pragurile posibile de decizie.